Unit 5: Principles of qualitative analysis
NEURO_QUAL Podcast Principles of Qualitative Analysis
5.1 Unit introduction
Welcome to Unit Five where you will learn about the principles of qualitative data analysis (QDA). You will be introduced to the general principles of what to do with qualitative data and how to use it to answer your qualitative research question. Each step in the process is described to help you undertake QDA and be confident in the outcome. We will explore different ways data can be analysed and decision making around suitable frameworks. Although we introduce several different analytical approaches, we focus in more detail on framework analysis and reflexive thematic analysis. The most common outcome of QDA are ‘themes and sub-themes’ which represent the data set, answer the research question, and reflect the philosophical/theoretical and methodological position underpinning the study.
Unit Content: Principles of qualitative analysis
- The aim of qualitative analysis
- Processing qualitative data ready for analysis
- Core principles of QDA
- An introduction to framework analysis and reflexive thematic analysis
- Good analysis and the importance of reflexivity
- Qualitative software
Reflection Point
Think for a moment about how qualitative researchers analyse their data.
Would you know what to do after qualitative data collection?
5.2 The aim of qualitative data analysis (QDA)
Like all analysis, the aim of QDA is to process raw data into something meaningful that will have wider implications than the study population from which it was drawn. In quantitative studies, data are usually processed by adding the data to a table or spreadsheet. To identify what is important in the data, a descriptive and/or inferential statistical calculation is conducted. The aim of quantitative analysis is usually generalisation. In qualitative research, the data also need to be processed and the important aspects of the data identified; but in contrast to quantitative analysis, there are no statistical tests that do this. Furthermore, the aim of qualitative analysis is [transferability] not generalisability (see Unit Six for a discussion of transferability). Instead of using P values to identify what is significant in the data, in QDA it is the researcher who has to make decisions about what is and is not important within a data set.
5.3 Planning for QDA
The approach to QDA should be determined during protocol development, and proper consideration should be given to the volume of data to be collected and the amount of time available to complete the analysis as required. There are lots of different ways to analyse data, and no one way is ‘better’ than the other. If you think back to the different philosophical approaches to qualitative research in Unit One and the continuum of qualitative research in Unit Two, you will remember that qualitative research is extremely heterogeneous; given this position, the ‘best’ qualitative analysis is that which is congruent with the philosophical underpinning of the study, its theoretical framework and its methodology. For example, if an interpretive stance is adopted, then descriptive analysis is not appropriate. And if a specific theoretically informed design is used, such as [grounded theory] or [narrative inquiry], then there are specific analytical strategies for these approaches (e.g. grounded theorists use [constant comparison], while those using narrative inquiry would normally use [narrative analysis]).
However, there is some flexibility in qualitative research which allows those who have not aligned their study with specific ontological/epistemological positions, or those who have not designed their study within a specific system of inquiry, to be more flexible over their choice of QDA framework. In this sense, QDA can be seen as a ‘tool kit’ with different approaches to select for different research problems. For example, a constant comparison analysis most commonly associated with grounded theory methodology can be used outside of a grounded theory study.
While having a robust analytical plan is particularly important, this flexibility in qualitative research means that a researcher may change their stance toward QDA during a study. For example, when an a priori analytical approach fails to yield the insights required to answer the research question, the researcher may decide to adopt a different analytical approach that will yield better insight into the phenomena under investigation. QDA is probably the most complex element of qualitative inquiry. Those attempting qualitative analysis for the first time, or researchers proposing a particularly complex analysis, would benefit from consulting an experienced qualitative researcher in much the same way as quantitative researchers consult statisticians.
Key Points: Planning for QDA
- Plan QDA during protocol development.
- Ensure QDA is appropriate for the philosophical/theoretical and methodological positioning of the study.
- Be aware of the volume of data that will be collected.
- Respect the time required for good analysis.
- Flexibility in the qualitative research process means plans for QDA can be adapted.
- If embarking on qualitative research for the first time, discuss analysis with a qualitative researcher.
5.4 Data processing
Whichever way data have been collected – written, verbal, observatory or imagery – this data needs to be turned into something that can be analysed. Most typically, for oral data this starts with transcription, which is a written account of the verbal data. While this may seem straightforward, there are still decisions to make about how the transcript should look and what should be included.
From a visual perspective, each document should have anonymised details of the participant, the date and time of the interview, and who was present. Margins should be wide on both sides of the text so that if printed these can be used to make notes. Alternatively, place the transcript in a table and use columns on either side. Using a large, clear font and double line spacing can also help make the transcript easy to read. Anonymity is important at the point of transcription, so be sure to change any revealing details like names and geographical locations. It may also be appropriate to change unique details (e.g. particular medical histories, places of work ) which, if shared, could reveal that person’s identity. Participants can be given random or chronological number identifiers (e.g. 529 or 01), or linked identifiers that use digits from postcodes and telephone numbers, for example (e.g. DE998173) – these create a link between the data and the subject, which may be needed in some studies (but importantly, do not use initials or dates of birth). Alternatively, you could use random pseudonyms (e.g. John, Mohamed, Olumide).
From a content perspective, a decision needs to be made about what will be transcribed – for example, non-verbal expressions, emotional responses, pauses, utterances, stutters. In addition, should the transcript be written to capture phonetical spelling and local dialect? These need to be consistent throughout a study, so decisions need to be taken at the outset. In this regard, many qualitative researchers will use ‘verbatim transcription’, which captures everything that occurred during the interview. Verbatim transcription can take a long time to complete, however; eight hours transcription time per one hour of interview data is not uncommon. In contrast, intelligent verbatim transcription will moderate what is transcribed in favour of the main verbal exchange, but not the more subtle cues that exist around it. Intelligent verbatim transcription can be quicker for studies, but it can result in data loss, so researchers should consider the potential impact on their ability to address the aim of their study. If time is limited in a study, and there are funds available, consider using a transcription service – or consider using transcription software, which may have an associated licence fee but may be free. But always check compliance to relevant privacy and data protection laws before sharing your data with a transcription service or transcription software. The researcher may, of course, want to transcribe the data themselves, as this has many benefits. If researcher transcription is preferred, there is equipment that can make this process easier, such as foot pedals for moving backwards and forwards in the audio file, which leaves your hands free to type.
Of course, if the data is already in a written form, this makes data processing easier. However, there are still decisions about presentation of raw data, anonymity, and recording contextual details such as dates, times, location etc.
Key Points: Data processing
- All data needs to be turned into something that can be analysed.
- Audio files are transcribed prior to QDA.
- During transcription, make sure data are anonymised – change names, people, places and any information that is unique and could reveal the participant’s identity.
- Transcripts should be easy to read and prepared for analysis (e.g. large, clear font; double line spacing; wide margins or columns).
- Decide what to transcribe and consider the impact of any data loss to the aim of the study.
- Consider the use of transcription services or software, but always check compliance to relevant data protection laws.
5.5 Data reduction
The large amount of data that can be generated in a relatively small qualitative study can be overwhelming. A one-hour interview, for example, can produce a written account of over 50 pages. Therefore, the aim of all analysis is to reduce the data down to something more manageable without losing the meaning or context of the data. This is facilitated through QDA procedures where researchers are trying to find some commonality or pattern within the data set. These commonalities can be clustered together into categories, often known as themes, which represent a participant’s shared account in a way that is honest, meaningful and respectful to their contribution. These resultant themes illustrate the problem under investigation and sometimes the solutions as well.
5.6 Getting to know your data
Many authors would argue that transcription is the first stage in analysis, because this is where the researcher gets to know their data well: a process called [‘immersion’]. During this phase, you should first take a broad overview of what the participant is trying to say. Then, go back to the data and look at it in a microscopic way, thinking more about ‘what else could they be saying here?’ Transcription is a great way to spend time with the data and really get to know it. Therefore, if the research team chooses to outsource transcription, immersion needs to happen in a different way, such as listening to audio files several times or reading transcripts several times prior to making any firm decisions about what may or may not be important in the data. Of course, the level of immersion will depend on the research question and the type of data collected. Some QDA stays at a surface level to describe the data; other QDA may look for meaning in what was not said as well as what was said.
Key Points: Getting to know the data
- Read and re-read the written data.
- Listen and re-listen to audio files.
- Think and reflect on what may be important in the data before making any firm decisions.
5.7 Beginning to code
After transcription and immersion, the researcher must break down the pages of raw data by locating the important information and sorting these into different categories. The way in which this is achieved is usually through ‘coding’ (but not always). Coding is a process by which the researcher labels parts of the transcript that are of interest to them.
“a code is a word or brief phrase that captures the essence of why you think a particular bit of data may be useful” 1 (p. 207)
“Codes are tags or labels for assigning units of meaning to the descriptive or inferential information compiled during a study. Codes usually are attached to ‘chunks’ of varying size-words, phrases, sentences, or whole paragraphs, connected or unconnected to a specific setting. They can take the form of a straightforward category label or a more complex one (e.g. metaphor).” 2 (p. 56)
Coding decisions can be deductive, inductive or both. In deductive coding, the research team will have an a priori framework (also known as a coding book) of what they want to identify in the data. In an inductive approach, the research team may want to be led by the data and have no a priori assumptions about what they want to find out, so they develop the coding book as they analyse their data. Depending on the qualitative methodology being used, codes can be fixed – i.e. once decided upon, the code does not change in response to the data; by contrast, coding can also be fluid, reflecting a more iterative process which evolves during data analysis as new information is uncovered and new understanding reached.
Prior to a coding book, knowing what to code and what not to code can be difficult. There are also no rules in QDA that says a 20-word sentence should be reduced to two codes, for example. However, code too much and you risk drowning the data; code too little and you risk a superficial analysis where much of the contextual data is omitted. Miles and Huberman2 suggests using the research question as an anchor and coding data that appear relevant to it. This approach provides some parameters for decisions about what to code and what not to code without expanding into areas that may not be relevant to your research. Another strategy is to code with another researcher; subsequent discussions about what to code and how to code can help advance the analysis as well as provide confidence and rigour in the process.
Depending on the methodology, QDA is often a mix of descriptive and interpretive codes. Descriptive codes (sometimes called data-derived, manifest or semantic codes) label exactly what can be identified and provide a useful summary of the explicit content of the data. In descriptive coding, the researcher maintains distance and separation from the objects of study – a position far more obviously associated with a post-positivist philosophy. In contrast, interpretive codes (sometimes called latent or researcher derived) go beyond the data through the application of conceptual and theoretical frameworks to examine implied meaning, which may be hidden deep within the data set.3 For example, not wearing a seat belt could be descriptively coded as ‘not wearing a seat belt’ or could be interpretively coded as ‘risk-taking behaviour’.
Figure 1 shows a short extract of coding to illustrate how coding can be done using different colours to represent different codes. The text not highlighted does not indicate this information is unimportant. Researchers should return to such areas and check if it should also be assigned a code and think about how this contextual information helps to aid interpretation.
Figure 1: Example of a coded transcript

Key Points: Beginning to code
- Coding is a process of labelling important parts of the data set.
- Coding decisions can be made a priori or in response to the data.
- Codes can be fixed or fluid.
- Coding can be facilitated with the help of another researcher.
- Codes can be descriptive or interpretive, or a mix of both.
5.8 Developing themes
While not all QDA results in themes, themes are by far the most common product of QDA procedures. In order to create themes, the researchers must work with their codes and cluster these into groups of codes that are similar. The iterative nature of qualitative research means that these codes may move in and out of clusters as the researcher begins to understand their meaning in more depth. The researcher will then work with the clusters and also bring similar clusters together to build categories. Once again, clusters may move in and out of categories as the researcher develops more confidence about how the data should be described or interpreted until a hierarchy is reached that is more stable and representative of the whole data set. The overarching categories are then identified as themes and the clusters of codes within them are usually called sub-themes. Each needs to be given a careful name that represents the data stored within it. Themes can be independent of each other or inter-related, and the researcher will need to explain this during the writing-up phase. Other types of QDA will go beyond themes and require a theory to be developed as well (e.g. grounded theory).
Figure 2: Hierarchical relationship between codes, sub-themes and themes
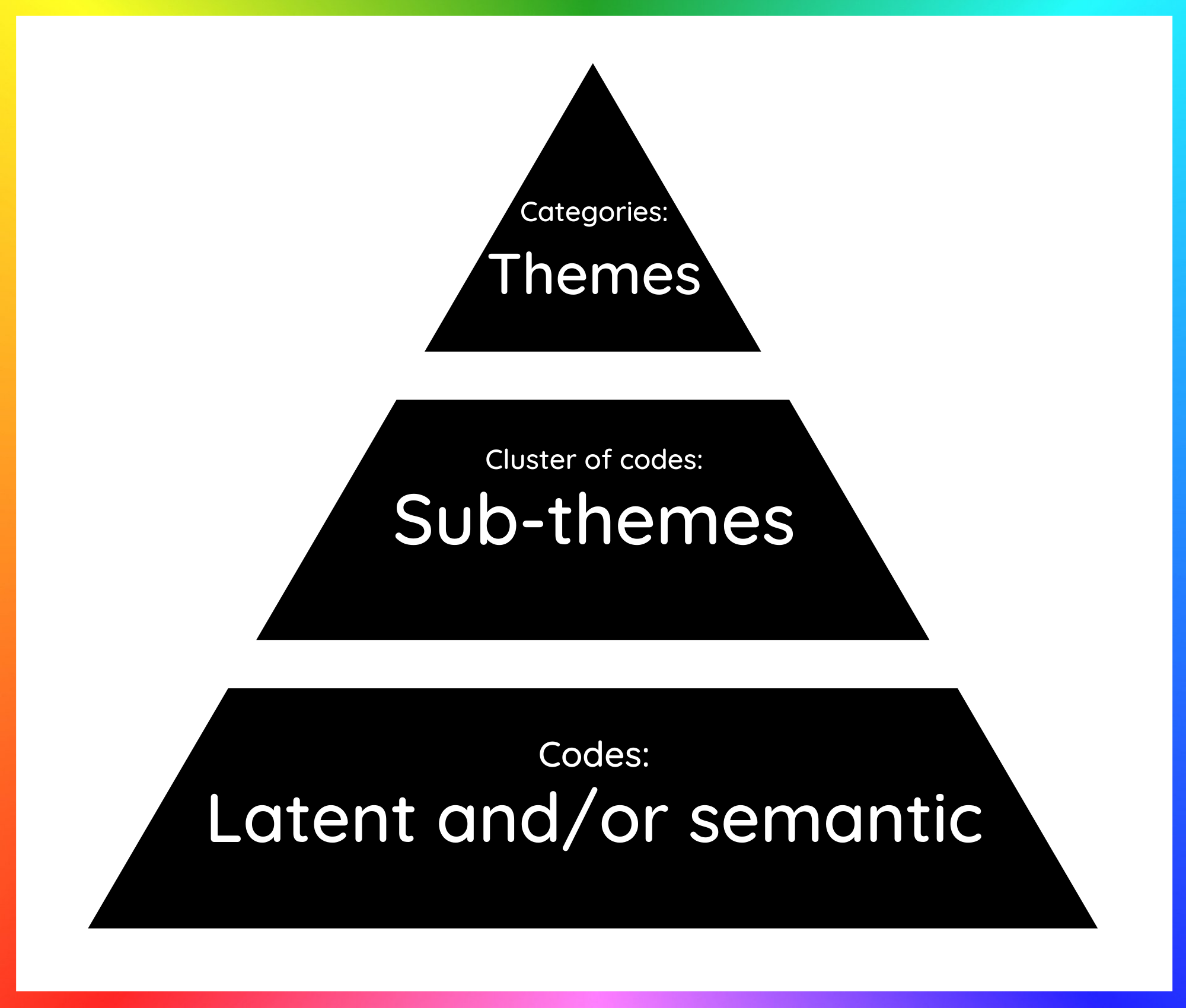
Key Points: Developing themes
- Themes are the most common product of QDA studies.
- Codes are clustered into related groups.
- Clusters of codes are then used to build broader categories.
- Categories become themes, clusters of codes become sub-themes and these are assigned appropriate names.
- Themes can be independent of each other or interrelated.
- Any relationships need to be explained in the write-up of the findings.
Recommended Reading
5.9 Analytical frameworks for QDA
There are lots of different analytical frameworks that can be used in qualitative research, and experience within the research team is particularly helpful in selecting the most appropriate for the study. While there are many differences, the frameworks also share some basic principles – see Box 1.
Box 1: Basic principles of QDA
| 1. Processing raw data into (usually) written material |
|---|
| 2. Immersion in the data through initial reading and listening to audio files |
| 3. Closer scrutiny of the text by coding the data |
| 4. Clustering codes, identifying a hierarchy of sub-themes and themes |
| 5. Testing out sub-themes and themes through negative cases analysis (what does not fit) |
| 6. Writing up the analysis into a comprehensive report |
Table 1 outlines some of the most common QDA techniques. Some are very prescriptive and rigid to follow, giving the researcher more scaffolding around their analysis. Others are less so, allowing the researcher to adopt a more immersive and open approach which may facilitate more interpretive analysis.
Table 1: Different approaches to QDA
| QDA Techique | Description |
|---|---|
| Content analysis | Examines the frequency of codes; the emphasis is on what can be explicitly identified in the data, rather than what may be implied. |
| Framework | Starts with a deductive stage mapping data against an a priori framework. An inductive stage follows to explore data that does not map to the original framework. |
| Reflexive thematic analysis (RTA) | A six-stage interpretive process (developed by Braun and Clarke6) to identify themes in the data. |
| Constant comparison | Origins in grounded theory but can be used outside this methodology. Very detailed analysis breaking the data apart, rebuilding and locating theory where appropriate. |
| Interpretive phenomological analysis (IPA) | A specific branch of interpretive phenomenology using a protocol-led process (Smith et al.7). |
| Discourse analysis | Analysis of language, based on examining the frequency of data items and the application of an interpretive approach to make sense of what the data items mean. |
| Within and between case analysis | Typical in case study research: comprehensive analysis of multiple forms of data within a ‘bounded system’ (i.e. ‘the case’) then there can be a comparison of data between different bounded systems (i.e. the cases). |
| Narrative analysis | Analysis of the ‘storied’ account with an emphasis on temporality (i.e. past, present and future). |
In this unit, we wanted to describe in more detail two QDA techniques commonly seen in the literature: framework analysis, and reflexive thematic analysis. Both lie outside of specific systems of inquiry like phenomenology or grounded theory, and both can be used to address a range of different qualitative research questions. However, if we use the analogy of Big Q and small q introduced in Unit One, framework analysis might be considered smaller q because it favours a deductive technique with an a priori framework and does not fully engage with the interpretive philosophy that is the hallmark of Big Q studies. That said, framework analysis is a very useful approach if the researchers have a fair idea of what it is they are interested in within the data and want to know in what way, and perhaps how often, these concepts arise. A further advantage of using framework analysis is the ability to examine data that do not fit neatly into the framework, and there is a final stage of interpretation to understand what the final data set means. See Table 2 for two approaches to framework analysis.
Table 2: Two approaches to framework analysis
| Framework analysis by Gale et al. 8 | Framework analysis by Ritchie and Spencer 9 |
|---|---|
| 1. Transcription (verbatim) 2. Familiarisation with the interview 3. Coding 4. Developing a working analytical framework 5. Applying the analytical framework* 6. Charting the data into the framework matrix 7. Interpreting the data * An analytical framework is a set of codes organised into categories that are used to manage and organise the data. |
1. Familiarisation 2. Identifying a thematic framework 3. Indexing and sorting 4. Charting 5. Mapping and Interpretation |
Reflexive thematic analysis, by contrast, is a flexible version of thematic analysis that does not have specific ontological and epistemological anchors10 but retains its commitment to reflexive interpretive analysis and as such is regarded as Big Q.
Reflexive Thematic Analysis 11
- 1 - Familarising yourself with your data
- 2 - Generate initial codes
- 3 - Searching for themes
- 4 - Reviewing themes
- 5 - Defining and naming themes
- 6 - Produce the report
Key Points: Analytical frameworks for QDA
- There are lots of QDA frameworks.
- Frameworks help the researcher to move systematically from data processing to final write-up.
- Techniques range from the highly descriptive (e.g. content analysis) to the highly interpretive (e.g. interpretive phenomenological analysis)
Reflection Point
Think about the qualitative analysis approaches described above. Do you immediately like or dislike the processes involved with any of these? If so, what is making you feel this way?
5.10 What is good analysis?
Good analysis should Illuminate the problem under investigation, be achievable given the time and resources available, and produce something that is careful, honest and accurate. Unlike quantitative analysis, QDA has no formula to identify what is and what is not important in the data. This means there is a ‘human factor’ to the analysis when making decisions about what to code and what the codes mean. The values, preferences and experiences of the researcher (known as axiology) are therefore central to all QDA procedures. Another important difference is that while quantitative researchers wait till all their data is collected to begin analysis, QDA is an ongoing process and researchers often analyse data at the same time as collecting data. Good QDA takes time and commitment to reflexivity. Mason12 wrote, ‘You must satisfy yourself and others that you have not invented or misrepresented your data, or been careless and slipshod in your recording and analysis of data’ (p.188).
Key Points: What is a good analysis?
- Illuminates the problem under investigation
- Achievable given time and resources
- Careful, honest and accurate
- Reflexive
5.11 Reflexivity
Reflexivity in QDA is defined as:
“active acknowledgement by the researcher that his/her own actions and decisions will inevitably impact on the meaning and context of the experience under investigation” 13 (p.308)
“The process of critical self-reflection about oneself as researcher (own biases, preferences, preconceptions), and the research relationship (relationship to the respondent, and how the relationship affects participant’s answers to questions” 14 (p.121)
If you adopt a post-positivist approach to QDA, the value of reflexivity may not seem obvious. However, in interpretive approaches reflexivity is key to QDA. For many researchers, instead of trying to minimise the influence of the researcher through the methods being used or to put aside all their assumptions (called bracketing), there is now more emphasis on being consciously aware of how these may be affecting the whole research process, and analysis in particular.15 Reflexivity is not just thinking about events and circumstances; instead, it demands that we question our own values, thought processes, assumptions and attitudes and how these influence our complex roles and relationships with others.16
The most common strategy to facilitate reflexivity is the maintenance of a reflexive journal. In the journal, the researcher critically explores their axiology and how their axiology is influencing the study. In the QDA phase, the researcher can also use the diary to posit ideas about relationships between codes or ideas they have for themes and sub-themes. It is very easy in qualitative research to make assumptions very quickly, so it is important to look at the data very closely. It is helpful to write down initial assumptions of the things that are going on in the data and challenge yourself to see if you are right in these assumptions, or if it’s possible that you could have misinterpreted something.
Reflexive diaries are also good for drawing or mapping out ideas about the data and what relationships may exist between these. These drawings may prove useful later on as a way to represent your data beyond the written word. They may also help advance beyond the themes into more abstract conceptualisations or theories about the phenomenon of interest. See Figure 3 for an example extract from a reflexive diary.
Figure 3: Illustration of a reflexive diary

In addition to reflexive diaries, memoing is another reflexive technique used during QDA. Although commonly associated with grounded theory, it is a useful strategy in other QDA approaches. Memoing is a process of making notes about what is being learnt about the data during analysis, how codes are being used to label data, or how codes may be related. Memoing can also be used when codes are contracted or expanded to create an [audit trail] of decision making in the analysis process. An audit trail is the documentation and transparent account of the steps taken from the outset of the study to the final report of the study findings. This is important to establish [credibility] in qualitative studies.
Figure 4: Illustration of a memo in NVivo

Reflection Point
What do you think to the diary extracts and memos presented above? How might these help a researcher?
Key Points: Reflexivity in QDA
- QDA is an active process.
- QDA requires conscious awareness of the influence the researcher has on the research.
- Researchers should keep a reflexive journal.
- Memoing is commonly used to make notes about specific areas of learning during the analysis process.
- Active reflexivity helps to creates an audit trail of decision making.
5.12 Analysis software
Computer software such as AtlasTI, NVivo and Quirkos can support QDA. However, it is important to be clear that this software will not analyse the data for the researcher; it merely facilitates the analytical process and is a useful way to store data, log coding decisions, write reflections and create memos all in one place. If used well, the resulting audit trail is a significant benefit for qualitative researchers. However, there are those who argue that using computer software separates the researcher from the data, and that this impedes immersion and limits the interpretive analysis. Such researchers often prefer a more ‘traditional’ and ‘hands on’ interaction with the data using highlighters, Post-it notes, and handwritten visual displays such as mind maps. Any decision to use or not use software should be carefully considered.
Access to software is usually through a licence and so has cost implications (you may find you have access via your institution), which should be built into the research budget. It is highly recommended that you attend training to use the software, which again has a cost implication.
Video: The NVivo Software
🎥 Click here to find a series of videos pertaining to the NVivo software suite.
5.13 Unit summary
In this unit, we examined how to turn data into findings and how to use a range of QDA techniques and methods. Reflecting the heterogeneity in the qualitative field, there is no one-size-fits-all approach to QDA. Instead, researchers must select an appropriate way to analyse their data that is appropriate for their philosophical, theoretical and/or methodological position. All data must be processed and reduced down to a useable product of research. Most commonly, findings are reported as themes which summarise the data set. To arrive at themes, the data must be broken down through coding procedures (or similar) and then rebuilt into something more useable and meaningful. Given the substantial influence of the ‘human factor’, researchers should understand how they are shaping the research and the analysis of the data. Reflexive practice will improve the process and product of qualitative research.
References
-
Braun V, Clarke V. Successful qualitative research: A practical guide for beginners. . London: SAGE 2013. ↩
-
Miles MB, Huberman AM. Qualitative data analysis : an expanded sourcebook. 2nd ed. ed. Thousand Oaks, Calif. ; London: Sage 1994. ↩↩
-
Kleinheksel AJ, Rockich-Winston N, Tawfik H, et al. Demystifying Content Analysis. Am J Pharm Educ 2020;84(1):7113. doi: 10.5688/ajpe7113 [published Online First: 2020/04/16] ↩
-
Saldaña J. The coding manual for qualitative researchers. 4th ed. Thousand Oaks: SAGE Publishing 2021. ↩
-
Silverman D. Interpreting qualitative data : a guide to the principles of qualitative research. 4th ed. ed. London: SAGE 2011. ↩
-
Braun V, Clarke V. Using thematic analysis in psychology. Qualitative Research in Psychology 2006;3(2):77-101. doi: 10.1191/1478088706qp063oa ↩
-
Smith JA, Larkin MH, Flowers P. Interpretative phenomenological analysis : theory, method and research. Los Angeles ; London: SAGE 2009. ↩
-
Gale NK, Heath G, Cameron E, et al. Using the framework method for the analysis of qualitative data in multi-disciplinary health research. BMC Med Res Methodol 2013;13:117. doi: 10.1186/1471-2288-13-117 [published Online First: 2013/09/21] ↩
-
Ritchie J, Spencer L. Qualitative data analysis for applied policy research. In: Bryman A, Burgess RG, eds. Analyzing qualitative data. London: Routledge 1994. ↩
-
Braun V, Clarke V, Weate P. Using thematic analysis in sport and exercise research. In: Smith B, Sparkes AC, eds. Routledge handbook of qualitative research in sport and exercise. London: Taylor & Francis (Routledge) 2016. ↩
-
Braun V, Clarke V. What can "thematic analysis" offer health and wellbeing researchers? Int J Qual Stud Health Well-being 2014;9:26152. doi: 10.3402/qhw.v9.26152 [published Online First: 2014/10/19] ↩
-
Mason J. Qualitative researching. 2nd ed. ed. London: SAGE 2002. ↩
-
Horsburgh D. Evaluation of qualitative research. J Clin Nurs 2003;12(2):307-12. doi: 10.1046/j.1365-2702.2003.00683.x [published Online First: 2003/02/27] ↩
-
Korstjens I, Moser A. Series: Practical guidance to qualitative research. Part 4: Trustworthiness and publishing. Eur J Gen Pract 2018;24(1):120-24. doi: 10.1080/13814788.2017.1375092 [published Online First: 2017/12/06] ↩
-
Ortlipp M. Keeping and Using Reflective Journals in the Qualitative Research Process. . The Qualitative Report 2008;13(4):695-705. doi: https://doi.org/10.46743/2160-3715/2008.1579 ↩
-
Bolton G. Reflective practice : writing and professional development. 3rd ed. ed. London: SAGE 2010. ↩